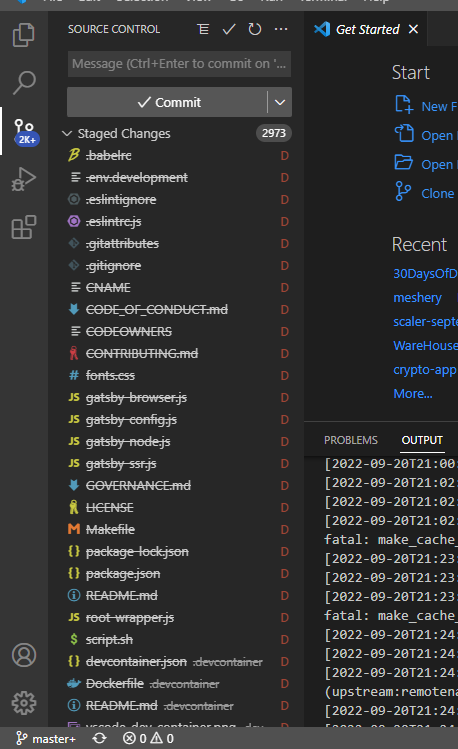
Regarding the challenge that you were having while cloning and running out of bandwidth, my previous recommendation is to shallow clone . Here are three ways to reduce clone sizes for repositories hosted by GitHub like layer5io/layer5:
-
git clone --filter=blob:none <url>creates a blobless clone. These clones download all reachable commits and trees while fetching blobs on-demand. These clones are best for developers and build environments that span multiple builds. -
git clone --filter=tree:0 <url>creates a treeless clone. These clones download all reachable commits while fetching trees and blobs on-demand. These clones are best for build environments where the repository will be deleted after a single build, but you still need access to commit history. -
git clone --depth=1 <url>creates a shallow clone. These clones truncate the commit history to reduce the clone size. This creates some unexpected behavior issues, limiting which Git commands are possible. These clones also put undue stress on later fetches, so they are strongly discouraged for developer use. They are helpful for some build environments where the repository will be deleted after a single build.
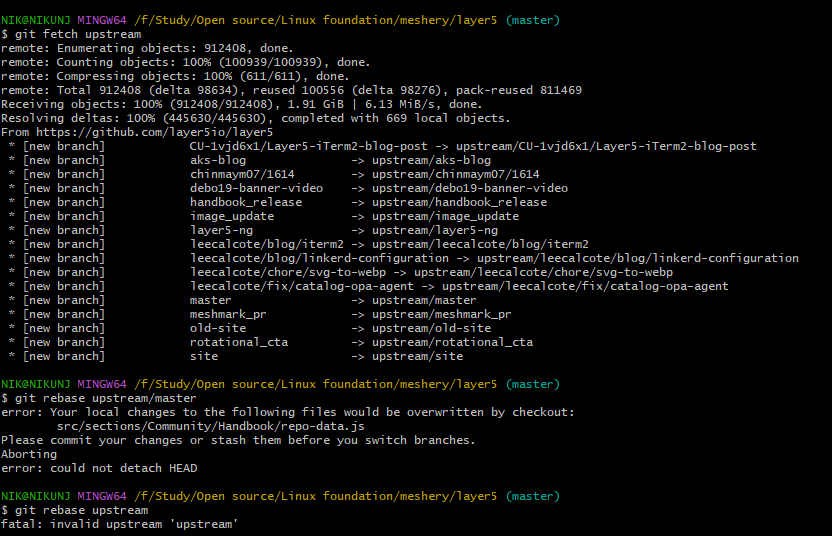
Regarding the error in this last screenshot, run a git stash, then continue from there (…git checkout master and so on).
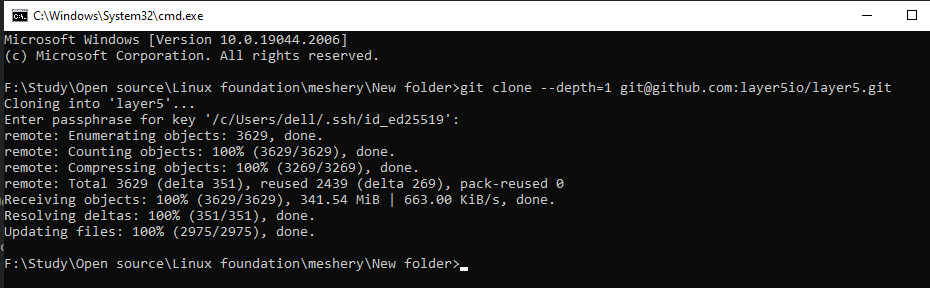
Thank you @Lee installed it successfully








